Сегодня я хотел бы вновь поговорить о 10 ГБ ограничении в SQL Server Express. В предыдущем посте я рассказал как можно разнести данные на несколько таблиц находящиеся в разных базах данных, что позволяет уйти от этого ограничения. И так наш сегодняшний гость это FileStream. С помощью него мы уйдем от ограничения в 10 ГБ на базу данных, позволяя хранить практически неограниченные объемы данных.
Достаточно часто встречаются базы данных в которых храняться бинарные данные большого объема. И если вы выбрали SQL Express то вы достаточно быстро подойдете к лимиту. Если вы конечно храните бинарные данные непосредствено в в файлах данных.
Сегодняшний пост посвящен именно этому случаю. У вас есть таблица с бинарными данными, и вы подходите или уже подошли к лимиту в 10 ГБ, который не дает вам дальше продолжать соранять данные в базу данных.
Итак начнем. Создаем базу для тестов, создаем в ней таблицу BlobData и заполняем бинарными данными.
Давайте теперь попробуем перейти на использование FileStream, наши бинарные данные находящиеся в таблице будут храниться непосредствено в файловой системе, а не в файлах данных БД. Для начала если ваш SQL Server Express не отконфигурирован на использование FileStream нужно сделать это. Вот инструкция. Также надо выставить параметр filestream_access_level, выполните следующий скрипт.
Теперь давайте добавим файловую группу для наших бинарных данныхю
Далее чтобы "магия" заработала нужно выполнить следующие действия:
Данные записались, никаких ошибок о привышении лимита. И в этом нет ничего удивительного, Express версия позволяет использовать FileStream который не имеет никаких органичений по объему хранимых данных.
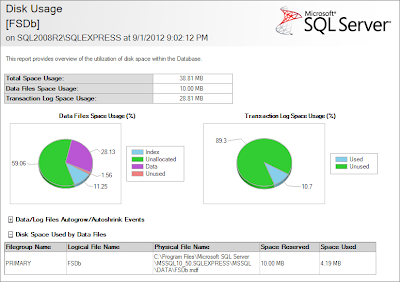
Вот скрин стандартного отчета по используемуму месту в БД, размер файла данных всего 10 МБ:
А вот как выглядят наши данные в файловой системе

Достаточно часто встречаются базы данных в которых храняться бинарные данные большого объема. И если вы выбрали SQL Express то вы достаточно быстро подойдете к лимиту. Если вы конечно храните бинарные данные непосредствено в в файлах данных.
Сегодняшний пост посвящен именно этому случаю. У вас есть таблица с бинарными данными, и вы подходите или уже подошли к лимиту в 10 ГБ, который не дает вам дальше продолжать соранять данные в базу данных.
Итак начнем. Создаем базу для тестов, создаем в ней таблицу BlobData и заполняем бинарными данными.
use master;
go
create database FSDb;
go
use FSDb;
go
create table dbo.BlobData (
id int identity (1, 1)
, ModTime datetime2(4)
, data varbinary(max)
, constraint PK_BlobData primary key clustered ( id )
)
go
with cte ( id )
as (
select 1
union all
select id + 1
from cte
where id < 10000
)
insert into dbo.BlobData ( ModTime, data )
select dateadd(day, -id, '20120901')
, convert(varbinary(max), '0x6a418c763f4d87b8e74663f4')
from cte
option ( maxrecursion 0 )
go
Давайте теперь попробуем перейти на использование FileStream, наши бинарные данные находящиеся в таблице будут храниться непосредствено в файловой системе, а не в файлах данных БД. Для начала если ваш SQL Server Express не отконфигурирован на использование FileStream нужно сделать это. Вот инструкция. Также надо выставить параметр filestream_access_level, выполните следующий скрипт.
exec sp_configure filestream_access_level, 1
reconfigure
Теперь давайте добавим файловую группу для наших бинарных данныхю
use master;
go
alter database FSDb
add filegroup filestreamgroup
contains filestream;
go
alter database FSDb
add file
(
NAME= 'FSDb_filestream',
FILENAME = 'c:\FSDb_filestream'
)
to filegroup filestreamgroup
go
Далее чтобы "магия" заработала нужно выполнить следующие действия:
use FSDb;
go
-- 1. добавляем уникальный идентификатор строки в
-- таблицу BlobData
alter table dbo.BlobData
add FileId uniqueidentifier not null
rowguidcol
default (newid())
unique
go
-- 2. указываем в каой файловой группе должны храниться
-- бинарные данные
alter table dbo.BlobData
set ( filestream_on = filestreamgroup )
go
-- 3. Создаем varbinary(max) поле и указываем что
-- это filestream
alter table dbo.BlobData
add DataFs varbinary(max) filestream null
go
-- 4. Перегоняем данные в новое поле
update dbo.BlobData
set DataFs = Data
go
-- 5. Удаляем старое поле Data (оно нам больше не
-- понадобиться)
alter table dbo.BlobData
drop column Data;
go
-- 6. Переименовываем поле DataFs в Data, так чтобы нам
-- не пришлось менять наше приложение или процедуры
-- которые обращаются к данным из этого столбца.
exec sp_rename
'dbo.BlobData.DataFs'
, 'Data'
, 'COLUMN';
-- создаем большой объект, примерно 344 MB
declare @Blob varchar(max)
= '16a418c763f4d87b0398e746a418c763f409812734'
, @i int = 0
while (@i < 23)
begin
set @Blob += @Blob
set @i += 1
end
--select len(@Blob)
-- а теперь записываем его в БД 50 раз. Это в районе 17 ГБ.
-- 344MB * 50 = 17200MB = 17.2GB
;with cte ( id )
as ( select 1
union all
select id + 1
from cte
where id < 50
)
insert into dbo.BlobData ( ModTime, data )
select dateadd(day, -id, '20120901')
, convert(varbinary(max), '0x' + @Blob)
from cte
go
Данные записались, никаких ошибок о привышении лимита. И в этом нет ничего удивительного, Express версия позволяет использовать FileStream который не имеет никаких органичений по объему хранимых данных.
Вот скрин стандартного отчета по используемуму месту в БД, размер файла данных всего 10 МБ:

А вот как выглядят наши данные в файловой системе




